2019년 10월 29일 화요일
데이터 사이언스 - 클러스터링 5가지 기법
데이터 과학자가 알아야 할
5가지 클러스터링 알고리즘
February 26,2018
클러스터링은 데이터 포인트의 그룹화와 관련된 머신러닝 기술입니다. 데이터 포인트 집합이 주어지면 클러스터링 알고리즘을 사용하여 각 데이터 포인트를 특정 그룹으로 분류 할 수 있습니다. 이론적으로 같은 그룹에 속한 데이터 요소는 비슷한 속성 및 / 또는 피처를 가져야 하지만 다른 그룹의 데이터 요소는 매우 다른 속성 및 / 또는 피처를 가지기도 합니다. 클러스터링은 비지도 학습의 한 방법이며 많은 분야에서 사용되는 통계 데이터 분석을 위한 공통 기술입니다.
데이터 과학에서는 클러스터링 알고리즘을 적용 할 때 데이터 포인트가 속하는 그룹을 확인함으로써 클러스터링 분석을 사용하여 데이터에서 가치있는 통찰력을 얻을 수 있습니다. 이 글에서는 데이터 과학자들이 알아야 할 5가지 인기 클러스터링 알고리즘의 장점과 단점을 살펴 보겠습니다.
1. K-Means Clustering
K-Means는 아마도 가장 잘 알고있는 클러스터링 알고리즘 일 것입니다. 그것은 많은 데이터 과학과 머신러닝수업에서 기본적으로 가르칩니다. 코드를 이해하고 구현하기 쉽습니다.
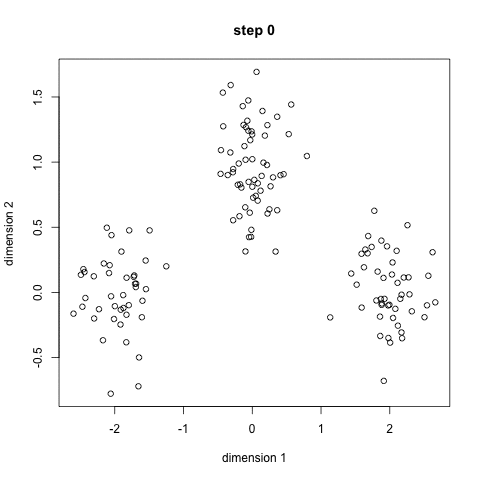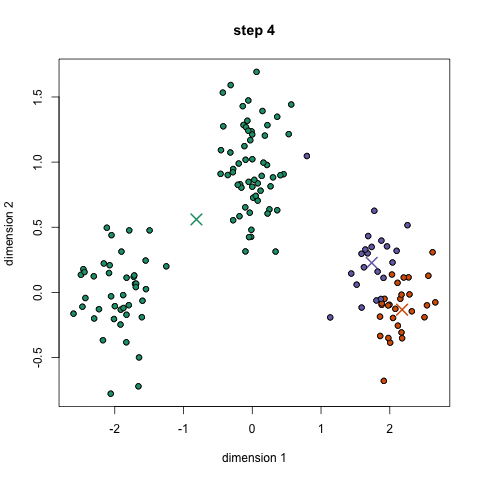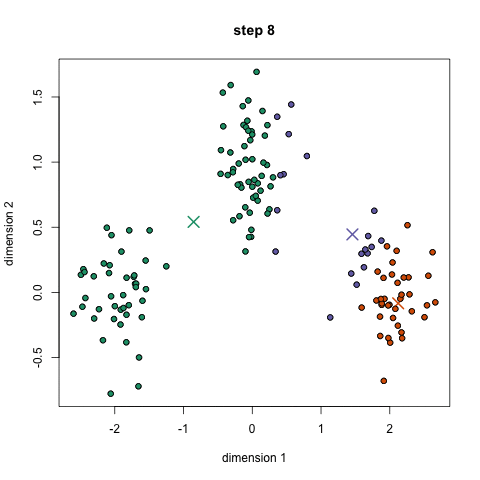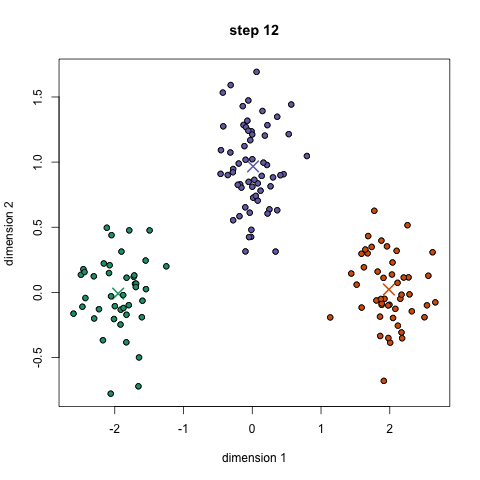
- 우선, 사용할 클래스 / 그룹을 선택하고 각각의 중심점을 무작위로 초기화합니다. 사용할 클래스의 수를 파악하려면 데이터를 빠르게 살펴보고 뚜렷한 그룹을 식별하는 것이 좋습니다. 중심점은 각 데이터 요소 벡터와 동일한 길이의 벡터이며 위의 그래픽에서 "X"입니다.
- 각 데이터 포인트는 해당 포인트와 각 그룹 센터 사이의 거리를 계산 한 다음 그 포인트가 가장 가까운 그룹에 속하도록 그룹화하여 분류됩니다.
- 이러한 분류된 점을 기반으로 그룹의 모든 벡터의 평균을 취하여 그룹 중심을 재 계산합니다.
- 설정된 반복 횟수 동안 또는 그룹 중심이 반복하는 사이에 많이 변하지 않을 때까지 이 단계를 반복하십시오. 그룹의 중앙을 무작위로 몇 번 초기화 한 다음 최상의 결과를 얻은 것처럼 보이는 실행을 선택할 수도 있습니다.
K-Means는 우리가 실제로 수행하는 모든 작업이 포인트와 그룹 중앙 사이의 거리를 계산하므로 매우 빠르다는 이점이 있습니다. 매우 적은 계산량으로 선형 복잡도 O ( n )을 갖습니다.
반면 K-Means에는 몇 가지 단점이 있습니다. 첫째, 얼마나 많은 그룹 / 클래스가 있는지 선택해야합니다. 이것은 항상 사소한 것은 아니며 클러스터링 알고리즘을 사용하면 이상적으로 데이터에서 통찰력을 얻는 것이므로 우리를 위해 알고리즘을 파악하는 것이 이상적입니다. K-Means는 또한 클러스터 중심의 무작위 선택으로 시작되므로 알고리즘을 실행할 때 마다 다른 클러스터링 결과를 산출 할 수 있습니다. 따라서 결과가 반복적이지 않고 일관성이 부족할 수 있습니다. 다른 클러스터 방법은 보다 일관성이 있습니다.
K-Medians는 그룹의 중앙 벡터를 사용하는 평균을 사용하여 그룹 중심점을 다시 계산하는 K-Means와 관련된 또 다른 클러스터링 알고리즘입니다. 이 방법은 (Median을 사용하기 때문에) 이상치에 덜 민감하지만 Median 벡터를 계산할 때 각 반복에서 정렬이 필요하므로 더 큰 데이터세트의 경우 훨씬 느립니다.
2. Mean-Shift Clustering
Mean shift 클러스터링은 데이터 포인트의 밀집된 영역을 찾기 위해 시도하는 슬라이딩 윈도우 기반 알고리즘입니다. 이는 중심점에 대한 후보를 슬라이딩 윈도우 내의 포인트의 평균으로 업데이트하여 작동하는 각 그룹 / 클래스의 중심점을 찾는 것이 목표라는 것을 의미하는 centroid 기반 알고리즘입니다. 이러한 후보 윈도우는 후 처리 단계에서 필터링되어 거의 중복을 제거하여 최종 세트의 중심점과 해당 그룹을 형성합니다.

- Mean shift을 설명하기 위해 위의 그림과 같이 2 차원 공간에서 일련의 점을 고려할 것입니다. 우리는 점 C (무작위로 선택됨)를 중심으로 반경 r이 커널을 중심으로하는 원형 슬라이딩 윈도우로 시작합니다. Mean shift는 융합이 될 때까지 각 단계에서이 커널을 반복적으로 고밀도 영역으로 이동시키는 hill climbing 알고리즘입니다.
- 모든 반복에서 슬라이딩 윈도우는 중심점을 윈도우 내의 점들의 평균 (따라서 이름)으로 이동시킴으로써 더 높은 밀도의 영역쪽으로 이동합니다. 슬라이딩 윈도우 내의 밀도는 그 안의 포인트의 수에 비례합니다. 당연히 윈도우에서 점의 평균으로 이동하면 점 밀도가 더 높은 영역으로 점차 이동합니다.
- 교대가 커널 내부에 더 많은 포인트를 수용 할 수 있는 방향이 없을 때까지 평균에 따라 슬라이딩 윈도우를 계속 이동시킵니다. 위의 그래픽을 확인하십시오. 더 이상 밀도를 증가시키지 않을 때까지 원을 움직입니다 (즉, 창에있는 점의 수).
- 이 1 ~ 3 단계 프로세스는 모든 점이 윈도우 안에 놓일 때까지 많은 슬라이딩 윈도우로 수행됩니다. 여러 개의 슬라이딩 윈도우가 겹치면 가장 많은 점을 포함한 윈도우가 유지됩니다. 그런 다음 데이터 포인트가 있는 슬라이딩 윈도우에 따라 데이터 포인트가 클러스터됩니다.
모든 슬라이딩 윈도우와 함께 엔드-투-엔드에서 전체 프로세스를 보여주는 그림은 아래와 같습니다. 검은색 점은 슬라이딩 윈도우의 중심을 나타내며 각 회색 점은 데이터 점입니다.

K-means 클러스터링과는 대조적으로, 평균 이동이 자동으로 이를 감지하여, 클러스터 수를 선택할 필요가 없습니다. 그것은 엄청난 이점입니다. 클러스터 센터가 최대 밀도 포인트로 수렴한다는 사실은 자연스러운 데이터 중심의 의미에서 이해하기 쉽고 잘 맞는 것처럼 매우 바람직합니다. 단점은 윈도우 크기 / 반경 "r"을 선택하는 것이 중요하지 않을 수 있다는 것입니다.
3. Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
DBSCAN은 mean-shift와 비슷한 밀도 기반의 클러스터된 알고리즘이지만 두드러진 장점이 있습니다. 아래의 그래픽을 확인하고 시작하겠습니다.
- DBSCAN은 방문하지 않은 임의의 시작 데이터 포인트로 시작합니다. 이 점의 근방은 거리 ε (ε 거리 내에있는 모든 점은 neighborhood point)을 사용하여 추출됩니다.
- 이 근처에 충분한 포인트 수가 있으면 (minPoints에 따라) 클러스터링 프로세스가 시작되고 현재 데이터 포인트가 새 클러스터의 첫번째 포인트가됩니다. 그렇지 않은 경우, 포인트는 노이즈로 레이블됩니다 (나중에이 노이즈 포인트가 클러스터의 일부가 될 수 있음). 두 경우 모두 해당 지점은 "visited"로 표시됩니다.
- 새로운 클러스터의 이 첫번째 점에 대해 ε 거리 인접도 내의 점도 동일한 클러스터의 일부가됩니다. 클러스터 그룹에 방금 추가 된 모든 새 점에 대해 동일한 클러스터에 속한 ε 근방에있는 모든 점을 만드는 이 절차가 반복됩니다.
- 이 2 단계와 3 단계 프로세스는 클러스터의 모든 점이 결정될 때까지 반복됩니다. 즉 클러스터의 ε 근처에있는 모든 점을 방문하여 레이블을 지정합니다.
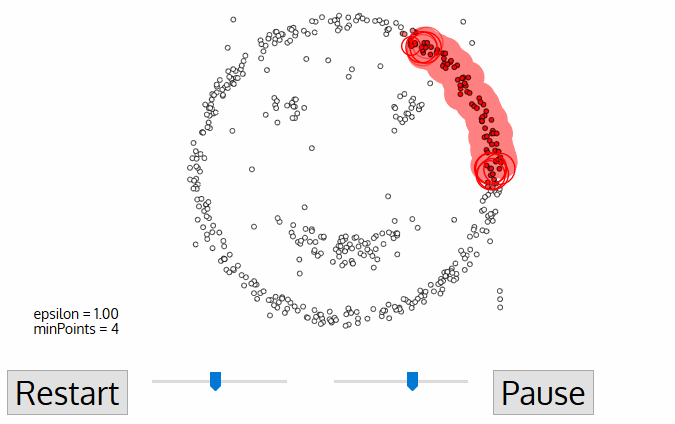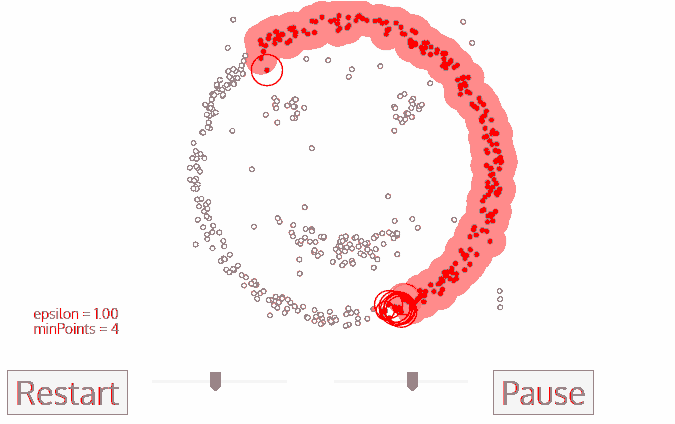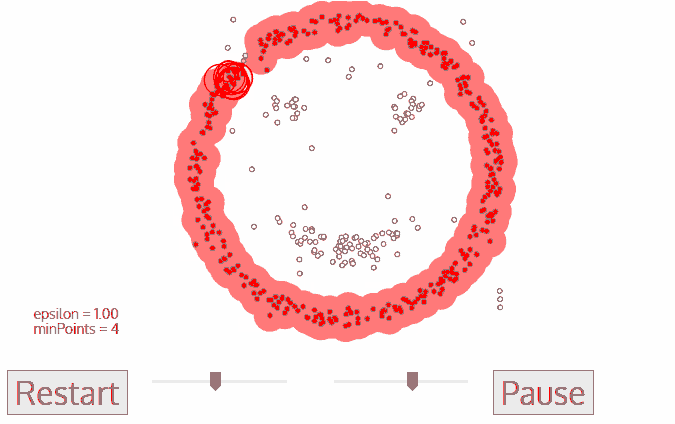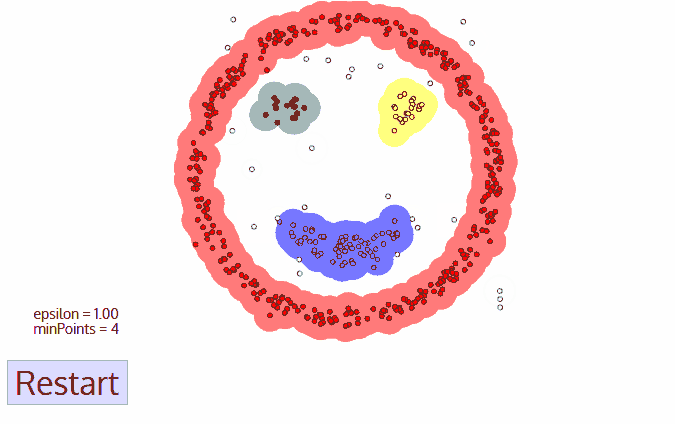
- 현재 클러스터를 완료하고 나면 새로운 미확인 지점이 검색되고 처리되어 추가 클러스터 또는 노이즈가 발견됩니다. 이 프로세스는 모든 포인트가 방문으로 표시 될 때까지 반복됩니다. 이 지점의 모든 지점을 방문 했으므로 각 지점은 클러스터에 속하거나 노이즈로 표시됩니다.
DBSCAN은 다른 클러스터링 알고리즘에 비해 큰 장점이 있습니다. 첫째로, 그것은 클러스터 집합을 전혀 필요로하지 않습니다. 또한 데이터 포인트가 매우 다르더라도 이상 값을 단순히 클러스터에 버리는 K-Means와는 달리 이상 치를 노이즈로 식별합니다. 또한 임의로 크기가 정해지고 임의로 모양이 지정된 클러스터를 매우 잘 찾을 수 있습니다.
DBSCAN의 가장 큰 단점은 클러스터의 밀도가 다양 할 때 다른 클러스터와 마찬가지로 잘 수행되지 않는다는 것입니다. 이는 밀도가 변할 때 neighborhood point를 식별하기위한 거리 임계 값 ε 및 minPoints의 설정이 클러스터마다 다양하기 때문입니다. 이 단점은 거리 임계치 ε가 다시 추정하기가 어려워지기 때문에 매우 고차원적인 데이터에서도 발생합니다.
4. Gaussian Mixture Models (GMM)을 사용한 Expectation-Maximization (EM) 클러스터링
K-Means의 주요 단점 중 하나는 클러스터 센터의 평균 값을 사용하는 것입니다. 왜 이것이 아래 이미지를 보면서 가장 좋은 방법이 아닌지 알 수 있습니다. 왼편에는 육안으로 볼 때 반경이 다른 두 개의 원형 클러스터가 같은 평균에 집중되어 있습니다. K-Means는 클러스터의 평균값이 매우 가깝기 때문에 이를 처리 할 수 없습니다. K-Means는 또한 클러스터가 원형이 아닌 경우에도 실패합니다. 다시 말하면 클러스터 평균을 클러스터 중심으로 사용한 결과입니다.

GMM(Gaussian Mixture Models)은 K-Means보다 더 많은 유연성을 제공합니다. GMM을 사용하여 데이터 포인트가 가우스 분포라고 가정합니다. 이는 평균을 사용하여 원형이라고 말하는 것보다 덜 제한적인 가정입니다. 그렇게하면 클러스터의 모양을 나타내는 두가지 파라미터가 있습니다 : 평균 및 표준 편차입니다. 2차원에서 예를 들자면, 이것은 클러스터가 모든 종류의 타원형을 취할 수 있음을 의미합니다 (x와 y 방향 모두에 표준 편차가 있으므로). 따라서 각 가우스 분포는 단일 클러스터에 할당됩니다.
각 클러스터 (예 : 평균 및 표준 편차)에 대한 가우스의 파라미터를 찾기위해 Expectation-Maximization (EM)이라는 최적화 알고리즘을 사용합니다. 아래 그래픽은 클러스터에 적합한 Gaussians의 그림입니다. 그런 다음 GMM을 사용하여 Expectation-Maximization(EM) 클러스터링 프로세스를 진행할 수 있습니다.
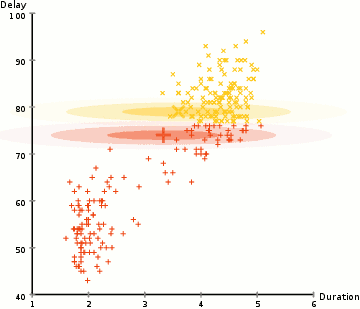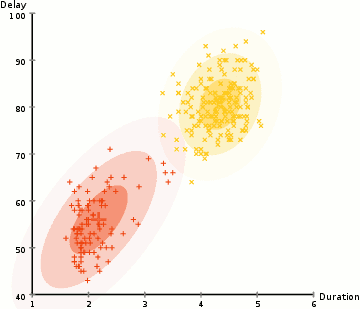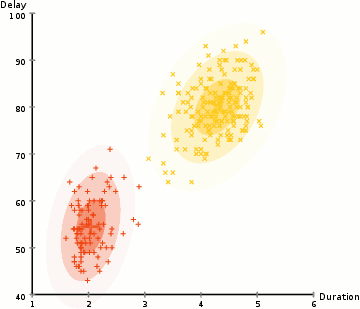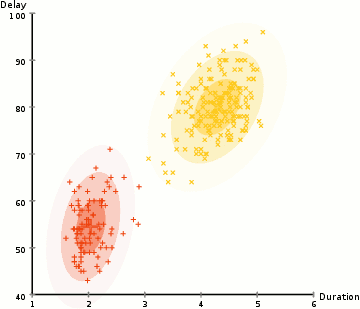
- 먼저 K-Means와 같은 클러스터 수를 선택하고 각 클러스터의 가우스 분포 파라미터를 무작위로 초기화합니다. 데이터를 빠르게 살펴봄으로써 초기 파라미터에 대한 좋은 추측을 제공 할 수 있습니다. 위의 그래픽에서 볼 수 있듯이 Gaussians이 매우 열악한 것으로부터 시작하지만 신속하게 최적화되기 때문에 이것은 100 % 필요하지 않습니다.
- 각 클러스터에 대해 이러한 가우시안 분포가 주어지면 각 데이터 포인트가 특정 클러스터에 속할 확률을 계산하십시오. 포인트가 가우스 중심에 가까울수록 그 클러스터에 속할 확률이 높습니다. 가우시안 분포를 사용하면 대부분의 데이터가 클러스터의 중심에 더 가깝다고 가정하므로 직관적으로 이해해야합니다.
- 이 확률에 기초하여 클러스터 내의 데이터 포인트의 확률을 최대화하기 위해 가우스 분포에 대한 새로운 파라미터 세트를 계산합니다. 데이터 포인트 위치의 가중치 합계를 사용하여 이러한 새 파라미터를 계산합니다. 여기서 가중치는 특정 클러스터에 속한 데이터 요소의 확률입니다. 이를 시각적으로 설명하기 위해 위의 그래픽을 살펴볼 수 있습니다. 특히 황색 클러스터를 예로들 수 있습니다. 첫번째 반복에서는 분포가 무작위로 시작되지만 노란색 점의 대부분이 해당 분포의 오른쪽에 있음을 알 수 있습니다. 확률로 가중치가있는 합계를 계산할 때 가운데 근처에 몇 가지 점이 있더라도 대부분이 오른쪽에 있습니다. 따라서 자연적으로 분포의 평균은 그 점 집합에 더 가깝게 이동합니다. 우리는 또한 대부분의 포인트가 "오른쪽 위에서 왼쪽"임을 알 수 있습니다. 따라서 표준 편차가 변경되어 확률에 의해 가중된 합을 최대화하기 위해 이러한 점에 더 적합한 타원을 만듭니다.
- 2 단계와 3 단계는 수렴에서 반복 될 때까지 반복됩니다. 여기서 수렴은 반복으로 많이 변하지 않습니다.
GMM 사용에는 실제로 두가지 주요 이점이 있습니다. 첫째, GMM은 K-Means보다 cluster covariance(공분산) 측면에서 훨씬 유연 합니다 . 표준 편차 파라미터로 인해 클러스터는 원으로 제한되기보다는 타원 모양을 취할 수 있습니다. K-Means는 실제로 모든 차원에서 각 클러스터의 공분산이 0에 가까워지는 GMM의 특별한 경우입니다. 둘째, GMM은 확률을 사용하기 때문에 데이터 포인트 당 여러 개의 클러스터를 가질 수 있습니다. 따라서 데이터 포인트가 두 개의 겹치는 클러스터의 중간에있는 경우 클래스 1에 X- 퍼센트, 클래스 2에 Y- 퍼센트로 속한다고 말하는 것으로 클래스를 정의 할 수 있습니다. 즉, GMM은 mixed membership을 지원 합니다.
5. Agglomerative Hierarchical Clustering
Hierarchical 클러스터링 알고리즘은 실제로 하향식 또는 상향식의 두가지 범주로 나뉩니다. 상향식 알고리즘은 각 데이터 포인트를 처음에는 단일 클러스터로 취급한 다음 모든 클러스터가 모든 데이터 포인트를 포함하는 단일 클러스터로 병합될 때까지 클러스터 쌍 을 연속적으로 병합 (또는 집적 )합니다. 따라서 상향식 계층적 클러스터링은 hierarchical agglomerative clustering 또는 HAC 라고 합니다 . 이 클러스터 계층 구조는 트리 (또는 dendrogram)로 표시됩니다. 트리의 루트는 모든 샘플을 수집하는 고유한 클러스터이며 하나의 샘플만 가진 클러스터입니다. 알고리즘 단계로 이동하기 전에 아래 그래픽을보고 그림을 확인하십시오.
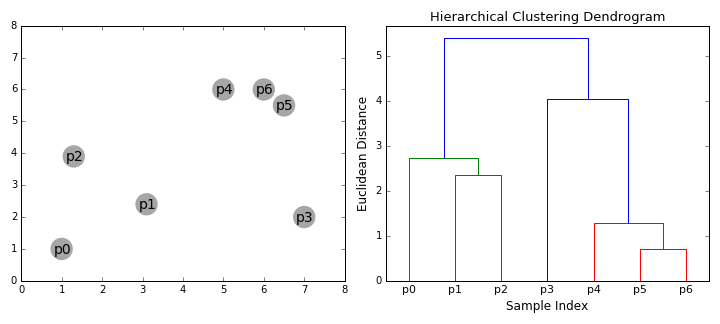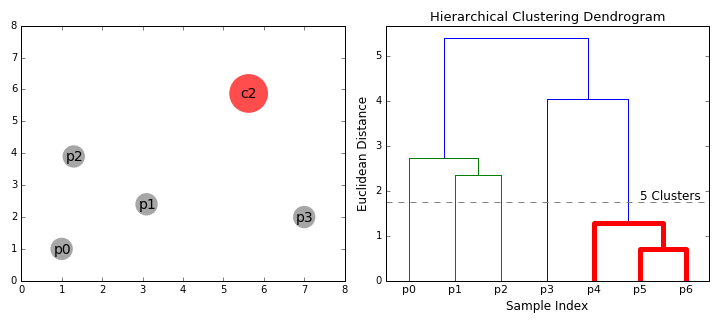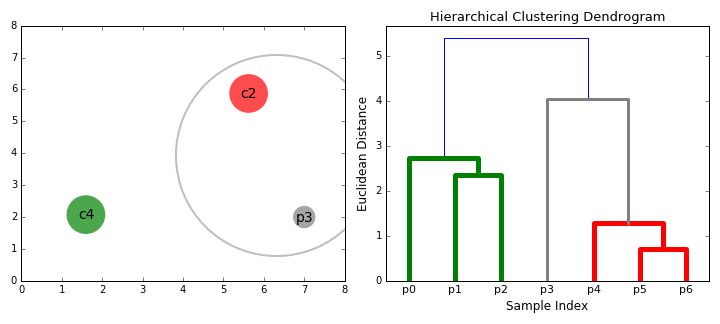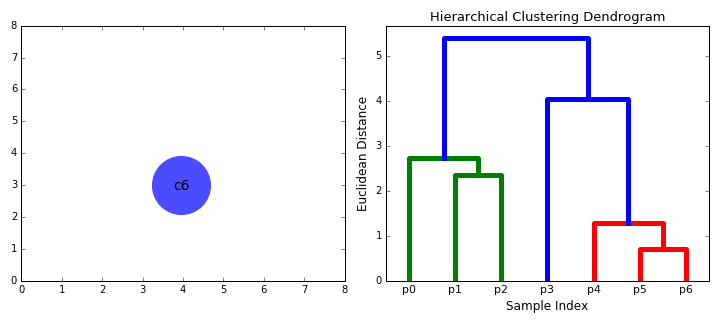
- 먼저 각 데이터 포인트를 단일 클러스터로 취급합니다. 즉, 데이터 세트에 X 데이터 포인트가 있는 경우 X 클러스터가 있습니다. 그런 다음 두 클러스터 간의 거리를 측정하는 거리 메트릭을 선택합니다. 예를 들어 두 클러스터 간의 거리를 첫번째 클러스터의 데이터 포인트와 두번째 클러스터의 데이터 포인트 사이의 평균 거리로 정의하는 average linkage를 사용 합니다.
- 매 반복마다 두 개의 클러스터를 하나로 결합합니다. 결합될 두 클러스터는 average linkage가 가장 적은 클러스터로 선택됩니다. 즉, 선택된 거리 메트릭에 따라 이 두 클러스터는 서로 가장 작은 거리를 가지므로 가장 유사하며 결합해야합니다.
- 2 단계는 트리의 루트에 도달 할 때까지 반복됩니다. 즉 모든 데이터 요소가 포함된 클러스터 하나만 있습니다. 이 방법으로 클러스터 구축을 중단 할 시점 즉, 트리 생성을 중단 할 때를 선택함으로써 결국 원하는 클러스터 수를 선택할 수 있습니다.
Hierarchical 클러스터링에서는 클러스터 수를 지정할 필요가 없으며 트리를 구축 할 때 가장 적합한 클러스터 수를 선택할 수도 있습니다. 또한 이 알고리즘은 거리 메트릭의 선택에 민감하지 않습니다. 이들 모두는 동등하게 잘 작동하는 경향이 있는 반면 다른 클러스터링 알고리즘에서는 거리 메트릭의 선택이 중요합니다. Hierarchical 클러스터링 방법의 특히 좋은 사용 사례는 기본 데이터가 계층 구조를 가지고 있고 계층 구조를 복구하려는 경우입니다. 다른 클러스터링 알고리즘은 이를 수행 할 수 없습니다. Hierarchical 클러스터링의 이러한 이점은 K-Means와 GMM의 선형 복잡성과 달리 O (n³) 의 시간 복잡성을 가지므로 효율성이 낮아지는 단점이 있습니다.
결론
데이터 과학자가 알아야하는 상위 5개의 클러스터링 알고리즘을 알아보았습니다. Scikit Learn으로 이러한 알고리즘과 몇가지 다른 알고리즘이 얼마나 잘 작동하는지 시각화하여 마무리하겠습니다.

원문
The 5 Clustering Algorithms Data Scientists Need to Know
George Seif
Certified Nerd. Lover of learning. AI / Machine Learning Engineer.
출처 : https://www.nextobe.com/single-post/2018/02/26/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EA%B3%BC%ED%95%99%EC%9E%90%EA%B0%80-%EC%95%8C%EC%95%84%EC%95%BC-%ED%95%A0-5%EA%B0%80%EC%A7%80-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%A7%81-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
2019년 9월 29일 일요일
2축 그래프 그리기
파이썬 - 2축 그래프 그리기
import numpy as np
import matplotlib.pyplot as plt
from random import *
x = np.arange(10)
y1 = [random() for _ in x]
y2 = [uniform(1,10) for _ in x]
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
data_y1 = ax1.plot(x, y1, color='b', linestyle='-.', marker='o', label='y1')
data_y2 = ax2.plot(x, y2, color='r', linestyle='--', marker='s', label='y2')
ax1.set_xlabel('x')
ax1.set_ylabel('data_y1')
ax2.set_ylabel('data_y2')
data_y = data_y1+data_y2
labels = [l.get_label() for l in data_y]
plt.legend(data_y, labels, loc=1)
plt.show()

# 각 y축의 범위 설정 방법
ax1.set_ylim(bottom, top)
ax2.set_ylim(bottom, top)
2019년 9월 24일 화요일
map() 함수
python map() 함수
python docs 의 map 함수에 대한 정의를 보자.
map(function, iterable, ...)
Apply function to every item of iterable and return a list of the results. If additional iterable arguments are passed, function must take that many arguments and is applied to the items from all iterables in parallel. If one iterable is shorter than another it is assumed to be extended with None items. If function is None, the identity function is assumed; if there are multiple arguments, map() returns a list consisting of tuples containing the corresponding items from all iterables (a kind of transpose operation). The iterable arguments may be a sequence or any iterable object; the result is always a list.
map() 함수는 built-in 함수로 list 나 dictionary 와 같은 iterable 한 데이터를 인자로 받아 list 안의 개별 item을 함수의 인자로 전달하여 결과를 list로 형태로 반환해 주는 함수이다. 글로 설명하면 복잡하니 아래 예제를 보자.
def func(x):
return x * 2
인자로 받은 정수를 두배로 곱하여 반환해 주는 매우 간단한 함수이다.
이 함수에 인자를 map() 함수를 이용해 전달해 보자.
>>> map( func, [1, 2, 3, 4] )
[2, 4, 6, 8]
위와 같이 map() 함수는 for문과 같은 반복문을 사용하지 않아도 지정한 함수로 인자를 여러번 전달해 그 결과를 list 형태로 뽑아 주는 유용한 함수이다. 한줄로 처리되다 보니 매우 간결한 형태의 코딩이 가능하다는 것이 큰 장점이다.
map() 함수의 경우 보통 위와 같이 인자를 list 형태로 전달하는게 일반적이지만 iterable 한 형태인 dictionary 같은 인자도 가능하다.
>>> x = { 1 : 10, 2 : 20, 3: 30 }
>>> map(func, x)
[ 2, 4, 6 ]
dictionary 의 key 값이 전달되게 되지만, 아래와 같이 조금만 응용하면 value 값을 전달하는 것도 가능하다.
>>> x = { 1 : 10, 2 : 20, 3: 30 }
>>> map(func, [ x[i] for i in x ])
[ 20, 40, 60 ]
[ 참고 ]
- https://docs.python.org/2/library/functions.html#map
출처: https://bluese05.tistory.com/58 [ㅍㅍㅋㄷ]
unix timestamp를 datatime으로 바꾸는 방법
Python Exercise: Convert unix timestamp string to readable date
Python datetime: Exercise-6 with Solution
Write a Python program to convert unix timestamp string to readable date.
Sample Solution:
Python Code:
Sample Output:
2010-09-10 13:31:22
피드 구독하기:
덧글 (Atom)
람다 표현식 (Lambda expression)
람다 표현식(Lambda expression) 람다 표현식으로 함수를 정의하고, 이를 변수에 할당하여 변수를 함수처럼 사용한다. (1) 람다 표현식 lambda <매개변수> : 수식 ※ 람다식을 실행하...

-
데이터 과학자가 알아야 할 5가지 클러스터링 알고리즘 February 26,2018 클러스터링은 데이터 포인트의 그룹화와 관련된 머신러닝 기술입니다. 데이터 포인트 집합이 주어지면 클러...
-
 Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What's In-Between 출처: < http:...
Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What's In-Between 출처: < http:... -
Spectral flatness or tonality coefficient , [1] [2] also known as Wiener entropy , [3] [4] is a measure used in digital signal proces...

